深度學(xué)習(xí)神經(jīng)網(wǎng)絡(luò)算法Transformer圖解
當(dāng)前位置:點(diǎn)晴教程→知識(shí)管理交流
→『 技術(shù)文檔交流 』
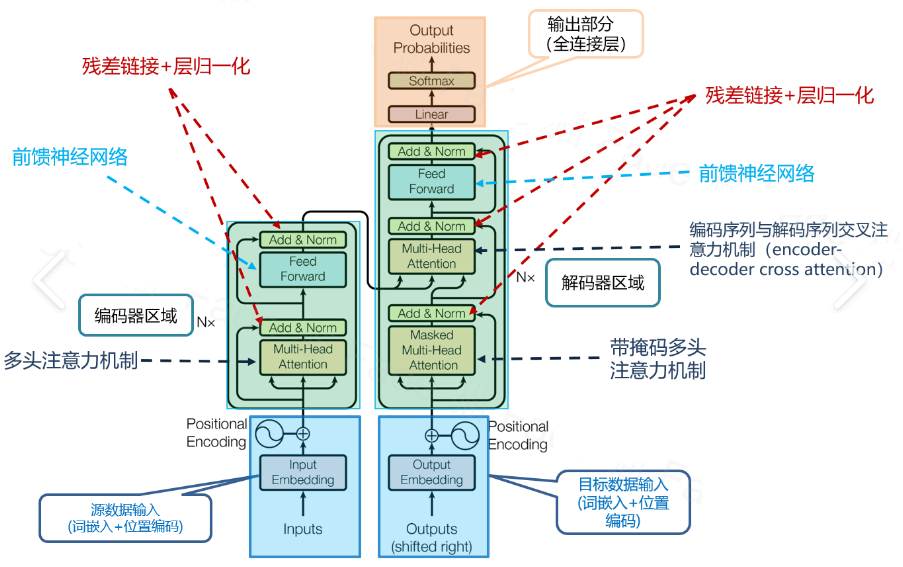
前言 transformer是目前NLP甚至是整個(gè)深度學(xué)習(xí)領(lǐng)域不能不提到的框架,同時(shí)大部分LLM也是使用其進(jìn)行訓(xùn)練生成模型,所以transformer幾乎是目前每一個(gè)機(jī)器人開發(fā)者或者人工智能開發(fā)者不能越過(guò)的一個(gè)框架。接下來(lái)本文將從頂層往下去一步步掀開transformer的面紗。 transformer概述 Transformer模型來(lái)自論文Attention Is All You Need。(https://arxiv.org/abs/1706.03762) 在論文中最初是為了提高機(jī)器翻譯的效率,它使用了Self-Attention機(jī)制和Position Encoding去替代RNN。后來(lái)大家發(fā)現(xiàn)Self-Attention的效果很好,并且在其它的地方也可以使用Transformer模型。并引出后面的BERT和GPT系列。 大家一般看到的transformer框架如下圖所示:
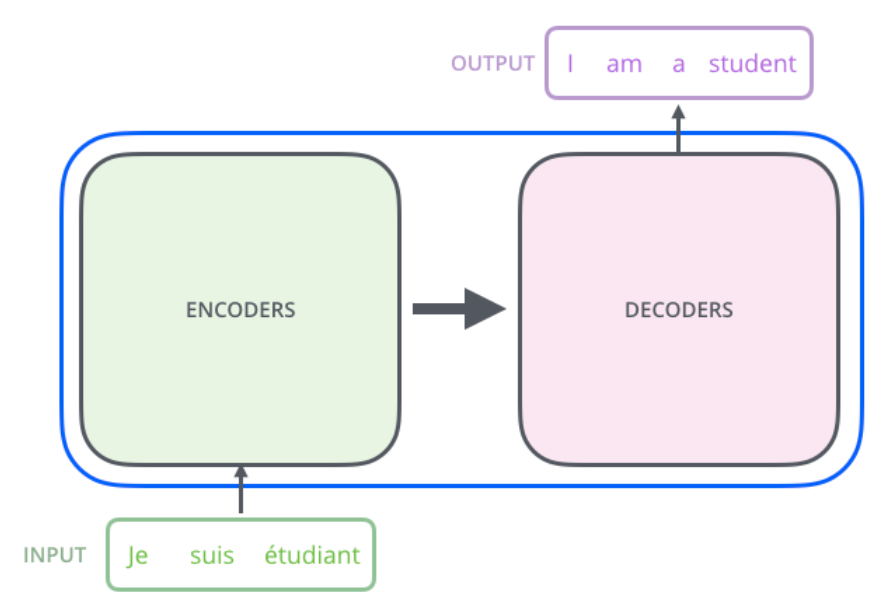
transformer模型概覽 首先把模型看成一個(gè)黑盒,如下圖所示,對(duì)于機(jī)器翻譯來(lái)說(shuō),它的輸入是源語(yǔ)言(法語(yǔ))的句子,輸出是目標(biāo)語(yǔ)言(英語(yǔ))的句子。
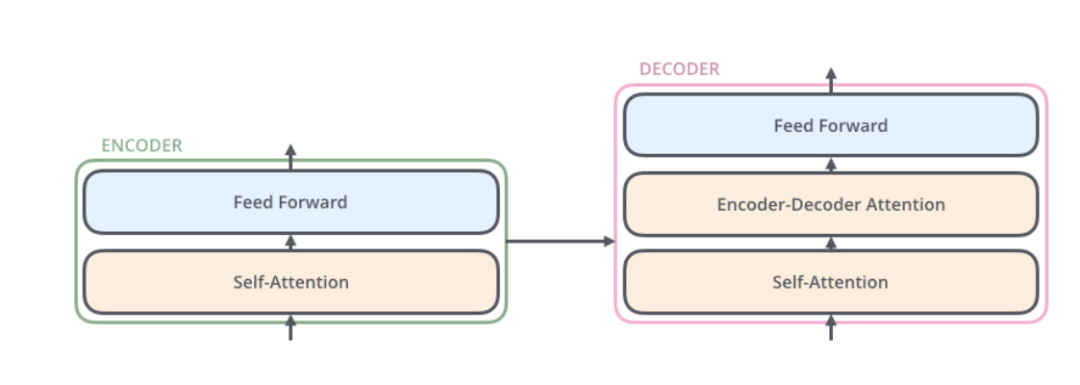
把黑盒子稍微打開一點(diǎn),Transformer(或者任何的NMT系統(tǒng))可以分成Encoder和Decoder兩個(gè)部分,如下圖所示。
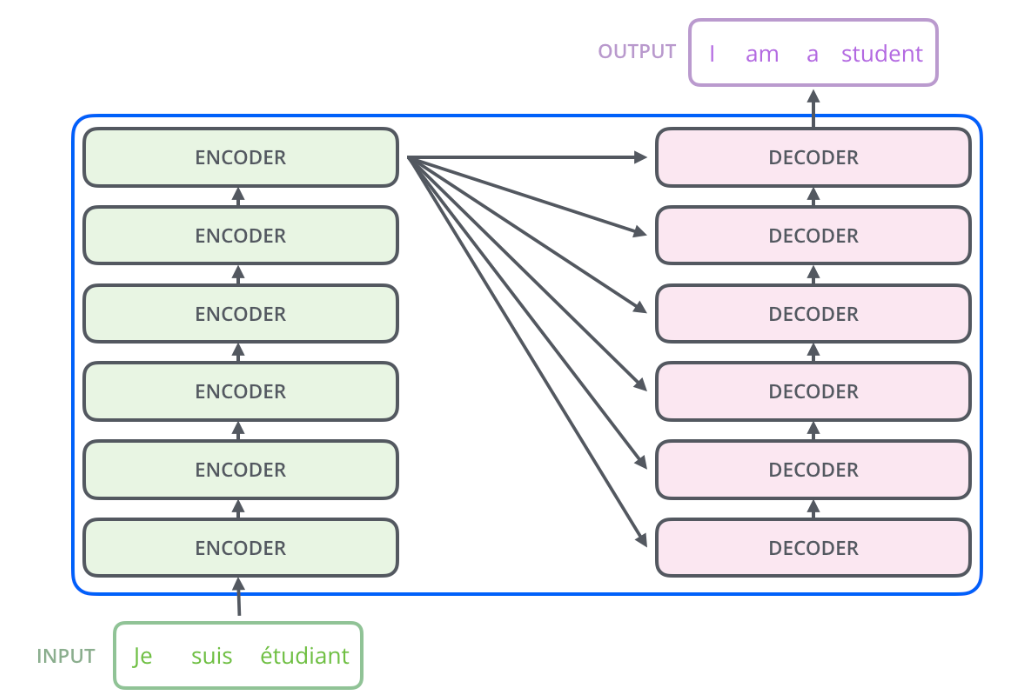
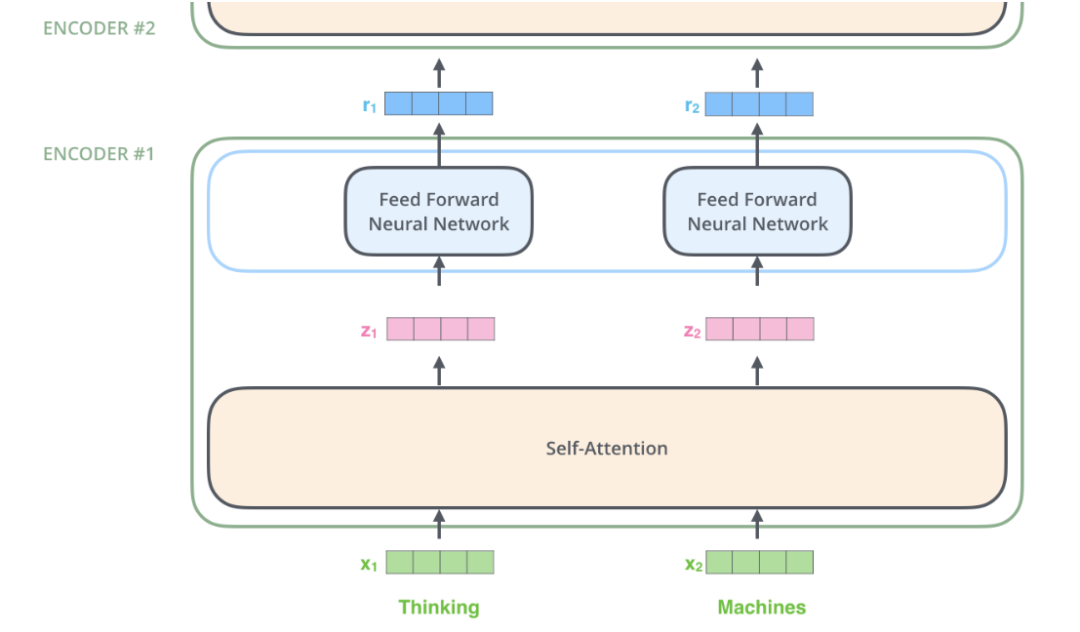
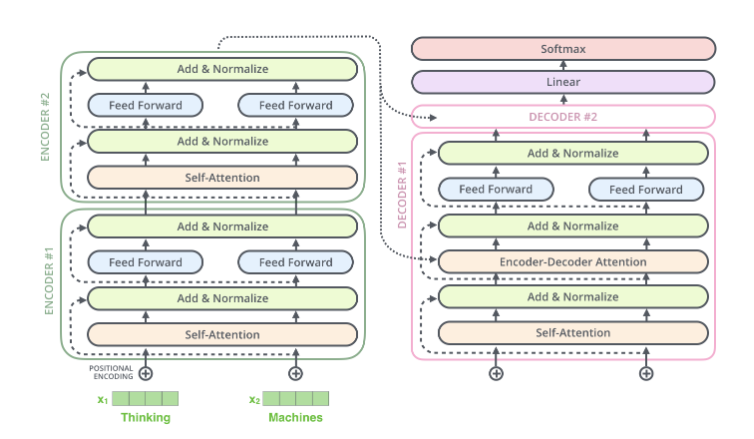
再展開一點(diǎn),Encoder由很多結(jié)構(gòu)一樣的Encoder堆疊而成,Decoder也是一樣。如下圖所示。 每一個(gè)Encoder的輸入是下一層Encoder輸出,最底層Encoder的輸入是原始的輸入(法語(yǔ)句子);Decoder也是類似,但是最后一層Encoder的輸出會(huì)輸入給每一個(gè)Decoder層,這是Attention機(jī)制的要求。
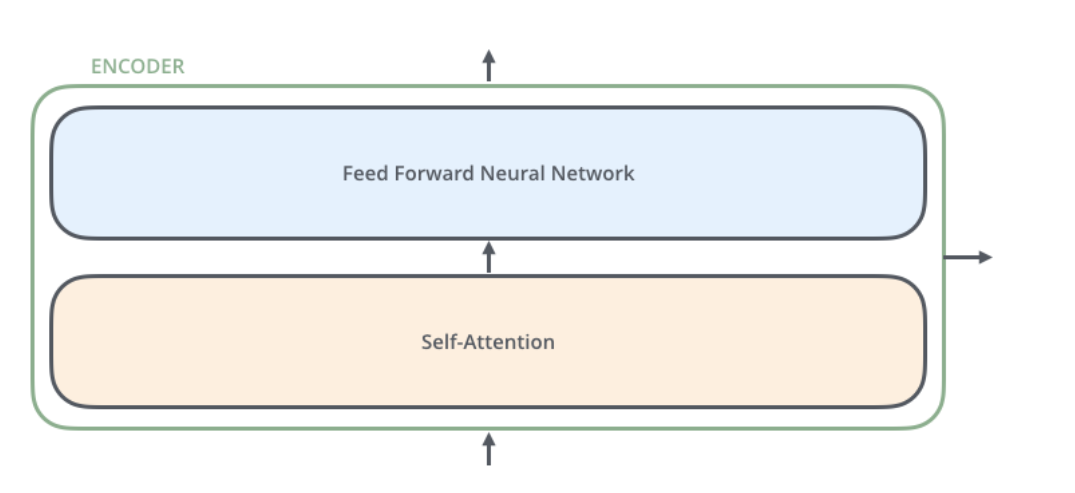
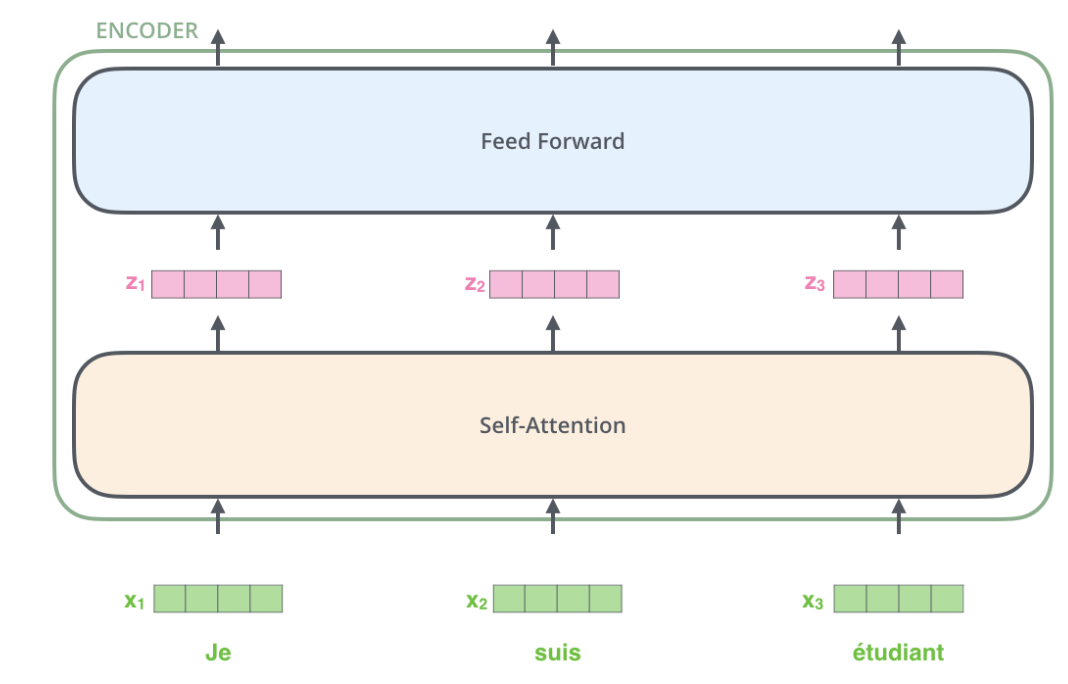
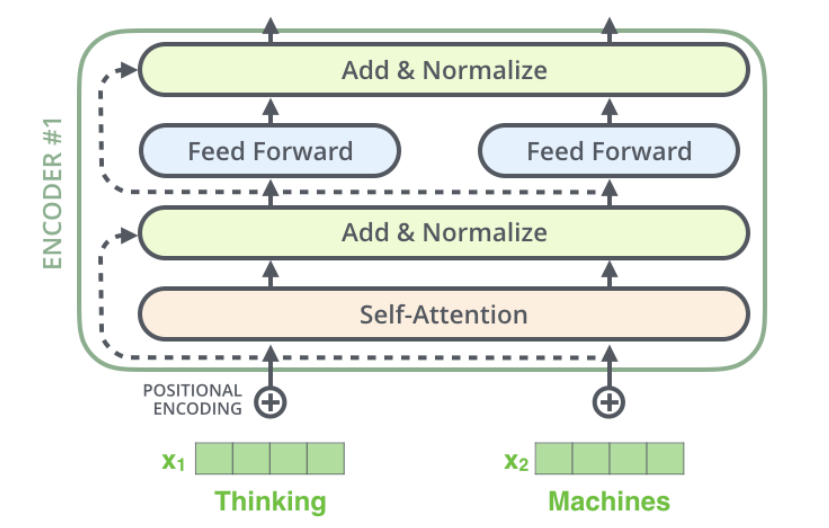
每一層的Encoder都是相同的結(jié)構(gòu),它由一個(gè)Self-Attention層和一個(gè)前饋網(wǎng)絡(luò)(全連接網(wǎng)絡(luò))組成,如下圖所示。
每一層的Decoder也是相同的結(jié)構(gòu),它除了Self-Attention層和全連接層之外還多了一個(gè)Attention層,這個(gè)Attention層使得Decoder在解碼時(shí)會(huì)考慮最后一層Encoder所有時(shí)刻的輸出。它的結(jié)構(gòu)如下圖所示。
transformer流程串聯(lián) transformer的串流需要tensor的加入,輸入的句子需要通過(guò)Embedding把它變成一個(gè)連續(xù)稠密的向量,如下圖所示。
Embedding之后的序列會(huì)輸入Encoder,首先經(jīng)過(guò)Self-Attention層然后再經(jīng)過(guò)全連接層。
我們?cè)谟?jì)算????時(shí)需要依賴所有時(shí)刻的輸入??1,…,????,這是可以用矩陣運(yùn)算一下子把所有的????計(jì)算出來(lái)的。而全連接網(wǎng)絡(luò)的計(jì)算則完全是獨(dú)立的,計(jì)算i時(shí)刻的輸出只需要輸入????就足夠了,因此很容易并行計(jì)算。下圖更加明確地表達(dá)了這一點(diǎn)。圖中Self-Attention層是一個(gè)大的方框,表示它的輸入是所有的??1,…,????,輸出是??1,…,????。而全連接層每個(gè)時(shí)刻是一個(gè)方框(但不同時(shí)刻的參數(shù)是共享的),表示計(jì)算????只需要????。此外,前一層的輸出??1,…,????直接輸入到下一層。
Self-Attention介紹 比如我們要翻譯如下句子”The animal didn’t cross the street because it was too tired”(這個(gè)動(dòng)物無(wú)法穿越馬路,因?yàn)樗哿?。這里的it到底指代什么呢,是animal還是street?要知道具體的指代,我們需要在理解it的時(shí)候同時(shí)關(guān)注所有的單詞,重點(diǎn)是animal、street和tired,然后根據(jù)知識(shí)(常識(shí))我們知道只有animal才能tired,而street是不能tired的。Self-Attention用Encoder在編碼一個(gè)詞的時(shí)候會(huì)考慮句子中所有其它的詞,從而確定怎么編碼當(dāng)前詞。如果把tired換成narrow,那么it就指代的是street了。 下圖是模型的最上一層Encoder的Attention可視化圖。這是tensor2tensor這個(gè)工具輸出的內(nèi)容。我們可以看到,在編碼it的時(shí)候有一個(gè)Attention Head(后面會(huì)講到)注意到了Animal,因此編碼后的it有Animal的語(yǔ)義。
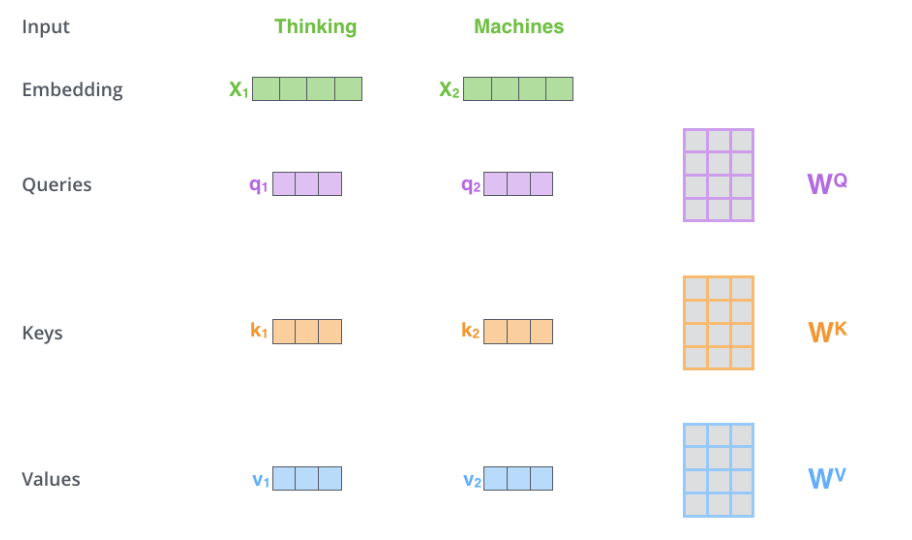
下面我們?cè)敿?xì)的介紹Self-Attention是怎么計(jì)算的,首先介紹向量的形式逐個(gè)時(shí)刻計(jì)算,這便于理解,接下來(lái)我們把它寫出矩陣的形式一次計(jì)算所有時(shí)刻的結(jié)果。 對(duì)于輸入的每一個(gè)向量(第一層是詞的Embedding,其它層是前一層的輸出),我們首先需要生成3個(gè)新的向量Q、K和V,分別代表查詢(Query)向量、Key向量和Value向量。Q表示為了編碼當(dāng)前詞,需要去注意(attend to)其它(其實(shí)也包括它自己)的詞,我們需要有一個(gè)查詢向量。而Key向量可以認(rèn)為是這個(gè)詞的關(guān)鍵的用于被檢索的信息,而Value向量是真正的內(nèi)容。 具體的計(jì)算過(guò)程如下圖所示。比如圖中的輸入是兩個(gè)詞”thinking”和”machines”,我們對(duì)它們進(jìn)行Embedding(這是第一層,如果是后面的層,直接輸入就是向量了),得到向量??1,??2。接著我們用3個(gè)矩陣分別對(duì)它們進(jìn)行變換,得到向量??1,??1,??1和??2,??2,??2。比如??1=??1????,圖中??1的shape是1x4,????是4x3,得到的??1是1x3。其它的計(jì)算也是類似的,為了能夠使得Key和Query可以內(nèi)積,我們要求????和????的shape是一樣的,但是并不要求????和它們一定一樣(雖然實(shí)際論文實(shí)現(xiàn)是一樣的)。
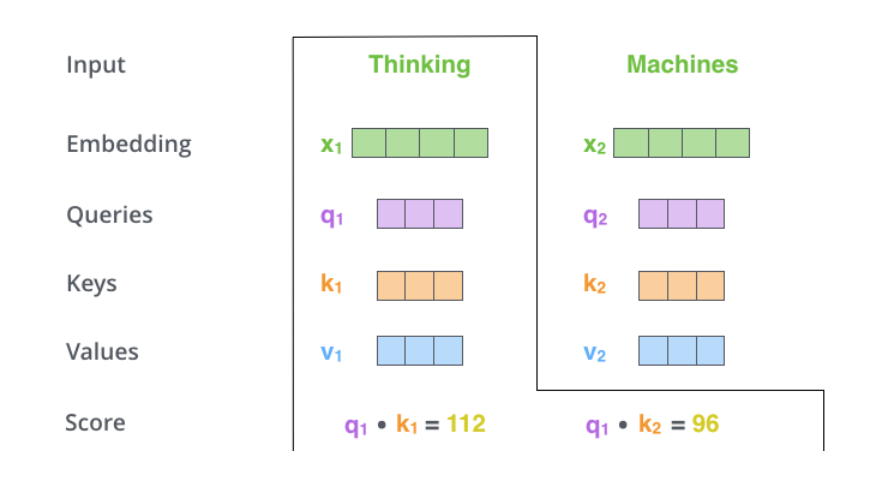
每個(gè)時(shí)刻t都計(jì)算出????,????,????之后,我們就可以來(lái)計(jì)算Self-Attention了。以第一個(gè)時(shí)刻為例,我們首先計(jì)算??1和??1,??2的內(nèi)積,得到score,過(guò)程如下圖所示。
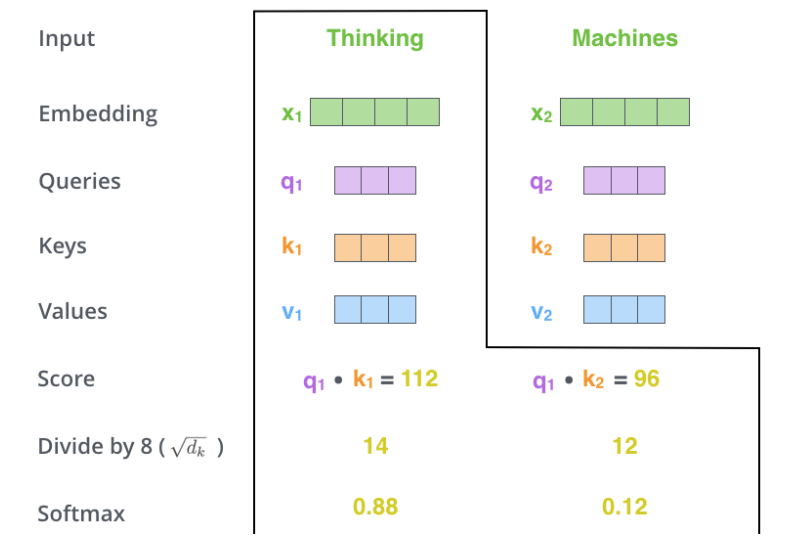
接下來(lái)使用softmax把得分變成概率,注意這里把得分除以8(????)之后再計(jì)算的softmax,根據(jù)論文的說(shuō)法,這樣計(jì)算梯度時(shí)會(huì)更加穩(wěn)定(stable)。計(jì)算過(guò)程如下圖所示。
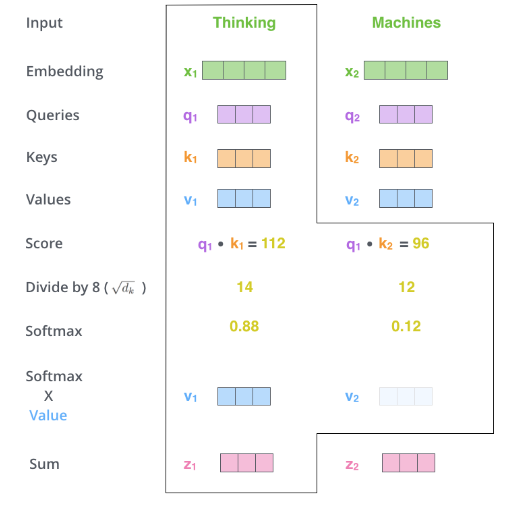
接下來(lái)用softmax得到的概率對(duì)所有時(shí)刻的V求加權(quán)平均,這樣就可以認(rèn)為得到的向量根據(jù)Self-Attention的概率綜合考慮了所有時(shí)刻的輸入信息,計(jì)算過(guò)程如下圖所示。
這里只是演示了計(jì)算第一個(gè)時(shí)刻的過(guò)程,計(jì)算其它時(shí)刻的過(guò)程是完全一樣的。 softmax示例代碼:
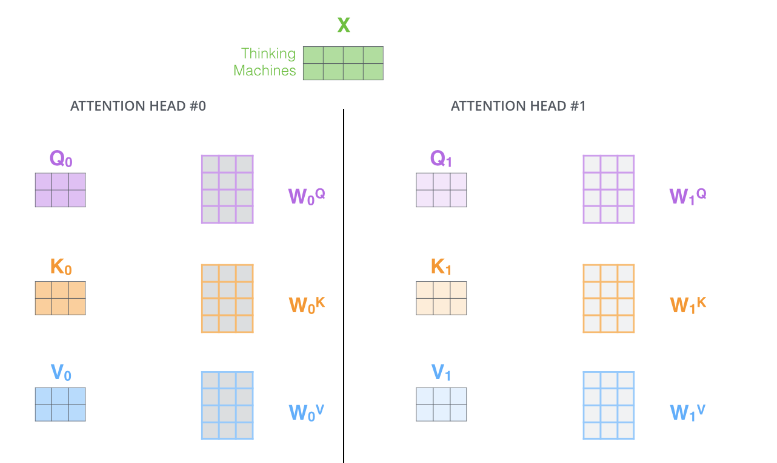
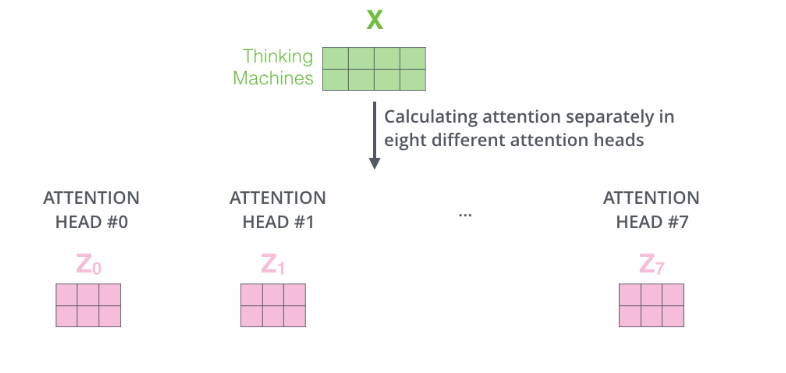
特別注意,以上過(guò)程是可以并行計(jì)算的。 Multi-Head Attention 論文還提出了Multi-Head Attention的概念。其實(shí)很簡(jiǎn)單,前面定義的一組Q、K和V可以讓一個(gè)詞attend to相關(guān)的詞,我們可以定義多組Q、K和V,它們分別可以關(guān)注不同的上下文。計(jì)算Q、K和V的過(guò)程還是一樣,不過(guò)現(xiàn)在變換矩陣從一組(????,????,????)變成了多組(????0,????0,????0) ,(????1,????1,????1)。如下圖所示。
對(duì)于輸入矩陣(time_step, num_input),每一組Q、K和V都可以得到一個(gè)輸出矩陣Z(time_step, num_features)。如下圖所示。
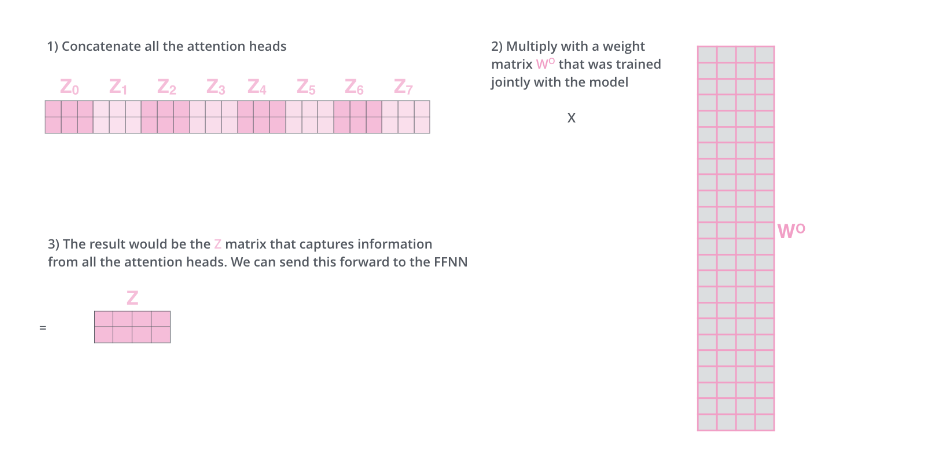
但是后面的全連接網(wǎng)絡(luò)需要的輸入是一個(gè)矩陣而不是多個(gè)矩陣,因此我們可以把多個(gè)head輸出的Z按照第二個(gè)維度拼接起來(lái),但是這樣的特征有一些多,因此Transformer又用了一個(gè)線性變換(矩陣????)對(duì)它進(jìn)行了壓縮。這個(gè)過(guò)程如下圖所示。
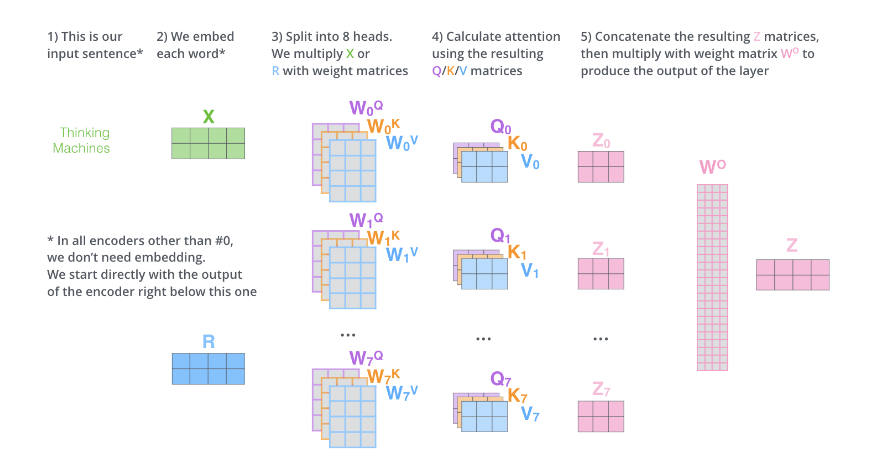
上面的步驟涉及很多步驟和矩陣運(yùn)算,我們用一張大圖把整個(gè)過(guò)程表示出來(lái),如下圖所示。
我們已經(jīng)學(xué)習(xí)了Transformer的Self-Attention機(jī)制,下面我們通過(guò)一個(gè)具體的例子來(lái)看看不同的Attention Head到底學(xué)習(xí)到了什么樣的語(yǔ)義。
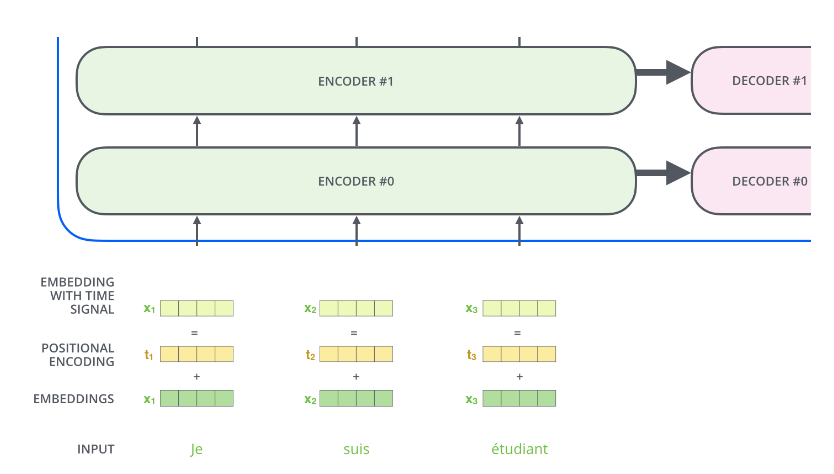
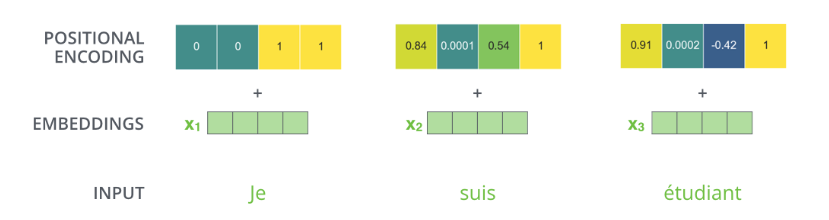
從上面兩圖的對(duì)比也能看出使用多個(gè)Head的好處——每個(gè)Head(在數(shù)據(jù)的驅(qū)動(dòng)下)學(xué)習(xí)到不同的語(yǔ)義。 位置編碼(Positional Encoding) 我們的目的是用Self-Attention替代RNN,RNN能夠記住過(guò)去的信息,這可以通過(guò)Self-Attention“實(shí)時(shí)”的注意相關(guān)的任何詞來(lái)實(shí)現(xiàn)等價(jià)(甚至更好)的效果。RNN還有一個(gè)特定就是能考慮詞的順序(位置)關(guān)系,一個(gè)句子即使詞完全是相同的但是語(yǔ)義可能完全不同,比如”北京到上海的機(jī)票”與”上海到北京的機(jī)票”,它們的語(yǔ)義就有很大的差別。我們上面的介紹的Self-Attention是不考慮詞的順序的,如果模型參數(shù)固定了,上面兩個(gè)句子的北京都會(huì)被編碼成相同的向量。但是實(shí)際上我們可以期望這兩個(gè)北京編碼的結(jié)果不同,前者可能需要編碼出發(fā)城市的語(yǔ)義,而后者需要包含目的城市的語(yǔ)義。而RNN是可以(至少是可能)學(xué)到這一點(diǎn)的。當(dāng)然RNN為了實(shí)現(xiàn)這一點(diǎn)的代價(jià)就是順序處理,很難并行。 為了解決這個(gè)問(wèn)題,我們需要引入位置編碼,也就是t時(shí)刻的輸入,除了Embedding之外(這是與位置無(wú)關(guān)的),我們還引入一個(gè)向量,這個(gè)向量是與t有關(guān)的,我們把Embedding和位置編碼向量加起來(lái)作為模型的輸入。這樣的話如果兩個(gè)詞在不同的位置出現(xiàn)了,雖然它們的Embedding是相同的,但是由于位置編碼不同,最終得到的向量也是不同的。 位置編碼有很多方法,其中需要考慮的一個(gè)重要因素就是需要它編碼的是相對(duì)位置的關(guān)系。比如兩個(gè)句子:”北京到上海的機(jī)票”和”你好,我們要一張北京到上海的機(jī)票”。顯然加入位置編碼之后,兩個(gè)北京的向量是不同的了,兩個(gè)上海的向量也是不同的了,但是我們期望Query(北京1)Key(上海1)卻是等于Query(北京2)Key(上海2)的。具體的編碼算法我們?cè)诖a部分再介紹。位置編碼加入后的模型如下圖所示。
一個(gè)具體的位置編碼的例子如下圖所示。
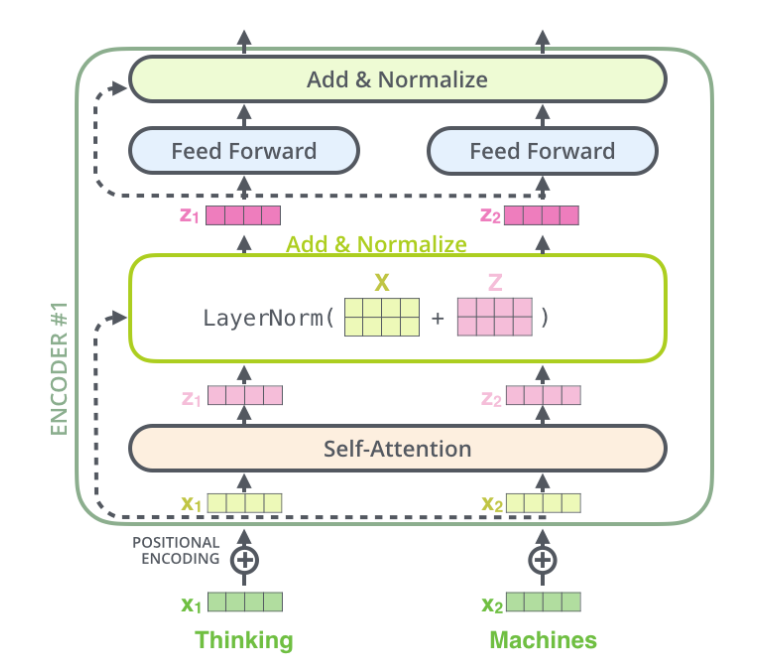
殘差和歸一化 每個(gè)Self-Attention層都會(huì)加一個(gè)殘差連接,然后是一個(gè)LayerNorm層,如下圖所示。
下圖展示了更多細(xì)節(jié):輸入??1,??2經(jīng)self-attention層之后變成??1,??2,然后和殘差連接的輸入??1,??2加起來(lái),然后經(jīng)過(guò)LayerNorm層輸出給全連接層。全連接層也是有一個(gè)殘差連接和一個(gè)LayerNorm層,最后再輸出給上一層。
Decoder和Encoder是類似的,如下圖所示,區(qū)別在于它多了一個(gè)Encoder-Decoder Attention層,這個(gè)層的輸入除了來(lái)自Self-Attention之外還有Encoder最后一層的所有時(shí)刻的輸出。Encoder-Decoder Attention層的Query來(lái)自前面一層,而Key和Value則來(lái)自Encoder的輸出。 此外在解碼器的編碼器-解碼器注意力層中,掩碼的使用非常關(guān)鍵,以確保解碼器在生成每個(gè)目標(biāo)詞時(shí)只能使用到源語(yǔ)言句子的信息和它之前已經(jīng)生成的目標(biāo)詞的信息
pytorch實(shí)現(xiàn)transformer
推理過(guò)程 在Transformer模型的機(jī)器翻譯任務(wù)中,解碼器生成第一個(gè)翻譯后的詞(通常稱為第一個(gè)目標(biāo)詞)的過(guò)程如下: 1、起始符號(hào):在解碼器的輸入序列的開始位置,通常會(huì)添加一個(gè)特殊的起始符號(hào),如<sos>(Start Of Sentence)。這個(gè)符號(hào)告訴模型翻譯過(guò)程的開始。 2、初始化隱藏狀態(tài):解碼器的隱藏狀態(tài)通常初始化為零向量或從編碼器的最后一層的輸出中獲得。這個(gè)隱藏狀態(tài)在生成序列的每一步中都會(huì)更新。 3、第一次迭代:在第一次迭代中,解碼器的輸入只包含起始符號(hào)<sos>。解碼器通過(guò)以下步驟生成第一個(gè)詞: ?將起始符號(hào) 通過(guò)嵌入層轉(zhuǎn)換為嵌入向量。 ?將這個(gè)嵌入向量與編碼器的輸出一起輸入到解碼器的第一個(gè)注意力層。 ?在自注意力層中,使用因果掩碼(Look-ahead Mask)確保解碼器只能關(guān)注到當(dāng)前位置和之前的詞(在這個(gè)例子中只有 )。 ?在編碼器-解碼器注意力層中,解碼器可以查看整個(gè)編碼器的輸出,因?yàn)檫@是第一次迭代,解碼器需要獲取關(guān)于整個(gè)源語(yǔ)言句子的信息。 ?經(jīng)過(guò)解碼器的前饋網(wǎng)絡(luò)后,輸出層會(huì)生成一個(gè)概率分布,表示下一個(gè)可能的詞。 ?選擇概率最高的詞作為第一個(gè)翻譯后的詞,或者使用貪婪策略、束搜索(Beam Search)等解碼策略來(lái)選擇詞。 4、后續(xù)迭代:一旦生成了第一個(gè)詞,它就會(huì)被添加到解碼器的輸入序列中,與<sos>一起作為下一步的輸入。在后續(xù)的迭代中,解碼器會(huì)繼續(xù)生成下一個(gè)詞,直到遇到結(jié)束符號(hào)<eos>或達(dá)到最大序列長(zhǎng)度。 在訓(xùn)練階段,目標(biāo)序列的真實(shí)詞(包括<sos>和<eos>)會(huì)用于計(jì)算損失函數(shù),并通過(guò)反向傳播更新模型的權(quán)重。在推理階段,解碼器使用上述過(guò)程逐步生成翻譯,直到生成完整的句子。 閱讀原文? 該文章在 2025/6/18 9:13:56 編輯過(guò) |
關(guān)鍵字查詢
相關(guān)文章
正在查詢... 晴ERP是一款針對(duì)中小制造業(yè)的專業(yè)生產(chǎn)管理軟件系統(tǒng),系統(tǒng)成熟度和易用性得到了國(guó)內(nèi)大量中小企業(yè)的青睞。")
晴PMS碼頭管理系統(tǒng)主要針對(duì)港口碼頭集裝箱與散貨日常運(yùn)作、調(diào)度、堆場(chǎng)、車隊(duì)、財(cái)務(wù)費(fèi)用、相關(guān)報(bào)表等業(yè)務(wù)管理,結(jié)合碼頭的業(yè)務(wù)特點(diǎn),圍繞調(diào)度、堆場(chǎng)作業(yè)而開發(fā)的。集技術(shù)的先進(jìn)性、管理的有效性于一體,是物流碼頭及其他港口類企業(yè)的高效ERP管理信息系統(tǒng)。")
晴WMS倉(cāng)儲(chǔ)管理系統(tǒng)提供了貨物產(chǎn)品管理,銷售管理,采購(gòu)管理,倉(cāng)儲(chǔ)管理,倉(cāng)庫(kù)管理,保質(zhì)期管理,貨位管理,庫(kù)位管理,生產(chǎn)管理,WMS管理系統(tǒng),標(biāo)簽打印,條形碼,二維碼管理,批號(hào)管理軟件。")
晴免費(fèi)OA是一款軟件和通用服務(wù)都免費(fèi),不限功能、不限時(shí)間、不限用戶的免費(fèi)OA協(xié)同辦公管理系統(tǒng)。")
|


 400 186 1886
400 186 1886
晴公司官網(wǎng)")