一文讀懂 Transformer 神經網絡模型
當前位置:點晴教程→知識管理交流
→『 技術文檔交流 』
自從最新的大型語言模型(LLaM)的發布,例如 OpenAI 的 GPT 系列、開源模型 Bloom 以及谷歌發布的 LaMDA 等,Transformer 模型已經展現出了其巨大的潛力,并成為深度學習領域的前沿架構楷模。
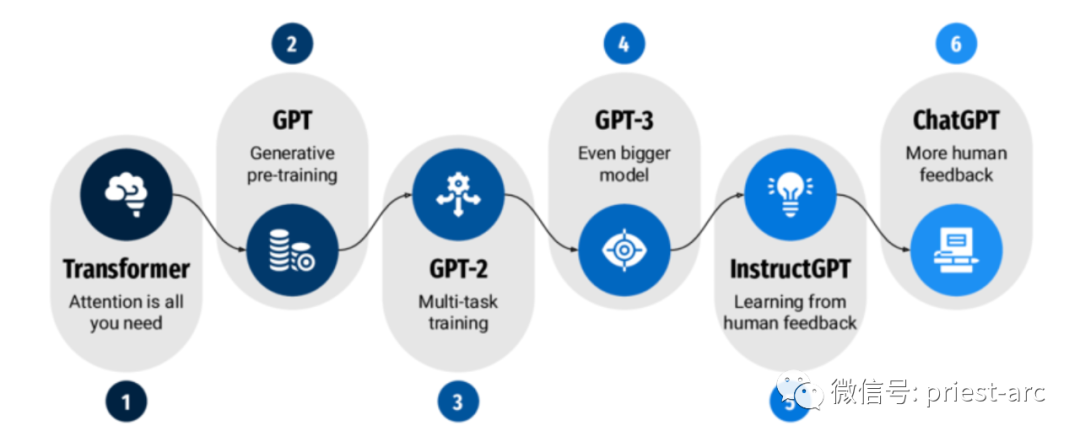
— 01 — 什么是 Transformer 模型 ?在過去幾年中,Transformer 模型已經成為高級深度學習和深度神經網絡領域的熱門話題。自從其在 2017 年被引入以來,Transformer 深度學習模型架構已經在幾乎所有可能的領域中得到了廣泛應用和演進。該模型不僅在自然語言處理任務中表現出色,還對于其他領域,尤其是時間序列預測方面,也具有巨大的幫助和潛力。 那么,什么是 Transformer 神經網絡模型? Transformer 模型是一種深度學習架構,自 2017 年推出以來,徹底改變了自然語言處理 (NLP) 領域。該模型由 Vaswani 等人提出,并已成為 NLP 界最具影響力的模型之一。 通常而言,傳統的順序模型(例如循環神經網絡 (RNN))在捕獲遠程依賴性和實現并行計算方面存在局限性。為了解決這些問題,Transformer 模型引入了自注意力機制,通過廣泛使用該機制,模型能夠在生成輸出時權衡輸入序列中不同位置的重要性。 Transformer 模型通過自注意力機制和并行計算的優勢,能夠更好地處理長距離依賴關系,提高了模型的訓練和推理效率。它在機器翻譯、文本摘要、問答系統等多個 NLP 任務中取得了顯著的性能提升。 除此之外,Transformer 模型的突破性表現使得它成為現代 NLP 研究和應用中的重要組成部分。它能夠捕捉復雜的語義關系和上下文信息,極大地推動了自然語言處理的發展。 — 02 — Transformer 模型歷史發展Transformer 在神經網絡中的歷史可以追溯到20世紀90年代初,當時 Jürgen Schmidhuber 提出了第一個 Transformer 模型的概念。這個模型被稱為"快速權重控制器",它采用了自注意力機制來學習句子中單詞之間的關系。然而,盡管這個早期的 Transformer 模型在概念上是先進的,但由于其效率較低,它并未得到廣泛的應用。 隨著時間的推移和深度學習技術的發展,Transformer 在2017年的一篇開創性論文中被正式引入,并取得了巨大的成功。通過引入自注意力機制和位置編碼層,有效地捕捉輸入序列中的長距離依賴關系,并且在處理長序列時表現出色。此外,Transformer 模型的并行化計算能力也使得訓練速度更快,推動了深度學習在自然語言處理領域的重大突破,如機器翻譯任務中的BERT(Bidirectional Encoder Representations from Transformers)模型等。 因此,盡管早期的"快速權重控制器"并未受到廣泛應用,但通過 Vaswani 等人的論文,Transformer 模型得到了重新定義和改進,成為現代深度學習的前沿技術之一,并在自然語言處理等領域取得了令人矚目的成就。 Transformer 之所以如此成功,是因為它能夠學習句子中單詞之間的長距離依賴關系,這對于許多自然語言處理(NLP)任務至關重要,因為它允許模型理解單詞在句子中的上下文。Transformer 利用自注意力機制來實現這一點,該機制使得模型在解碼輸出標記時能夠聚焦于句子中最相關的單詞。 Transformer 對 NLP 領域產生了重大影響。它現在被廣泛應用于許多 NLP 任務,并且不斷進行改進。未來,Transformer 很可能被用于解決更廣泛的 NLP 任務,并且它們將變得更加高效和強大。 有關神經網絡 Transformer 歷史上的一些關鍵發展事件,我們可參考如下所示: 1、1990年:Jürgen Schmidhuber 提出了第一個 Transformer 模型,即"快速權重控制器"。 2、2017年:Vaswani 等人發表了論文《Attention is All You Need》,介紹了 Transformer 模型的核心思想。 3、2018年:Transformer 模型在各種 NLP 任務中取得了最先進的結果,包括機器翻譯、文本摘要和問答等。 4、2019年:Transformer 被用于創建大型語言模型(LLM),例如 BERT 和 GPT-2,這些模型在各種 NLP 任務中取得了重要突破。 5、2020年:Transformer 繼續被用于創建更強大的模型,例如 GPT-3,它在自然語言生成和理解方面取得了驚人的成果。 總的來說,Transformer 模型的引入對于 NLP 領域產生了革命性的影響。它的能力在于學習長距離依賴關系并理解上下文,使得它成為眾多 NLP 任務的首選方法,并為未來的發展提供了廣闊的可能性。 — 03 — Transformer 模型通用架構設計Transformer 架構是從 RNN(循環神經網絡)的編碼器-解碼器架構中汲取靈感而來,其引入了注意力機制。它被廣泛應用于序列到序列(seq2seq)任務,并且相比于 RNN, Transformer 摒棄了順序處理的方式。 不同于 RNN,Transformer 以并行化的方式處理數據,從而實現更大規模的并行計算和更快速的訓練。這得益于 Transformer 架構中的自注意力機制,它使得模型能夠同時考慮輸入序列中的所有位置,而無需按順序逐步處理。自注意力機制允許模型根據輸入序列中的不同位置之間的關系,對每個位置進行加權處理,從而捕捉全局上下文信息。 代碼語言:javascript
代碼運行次數:0 運行
AI代碼解釋 代碼語言:javascript
代碼運行次數:0 運行
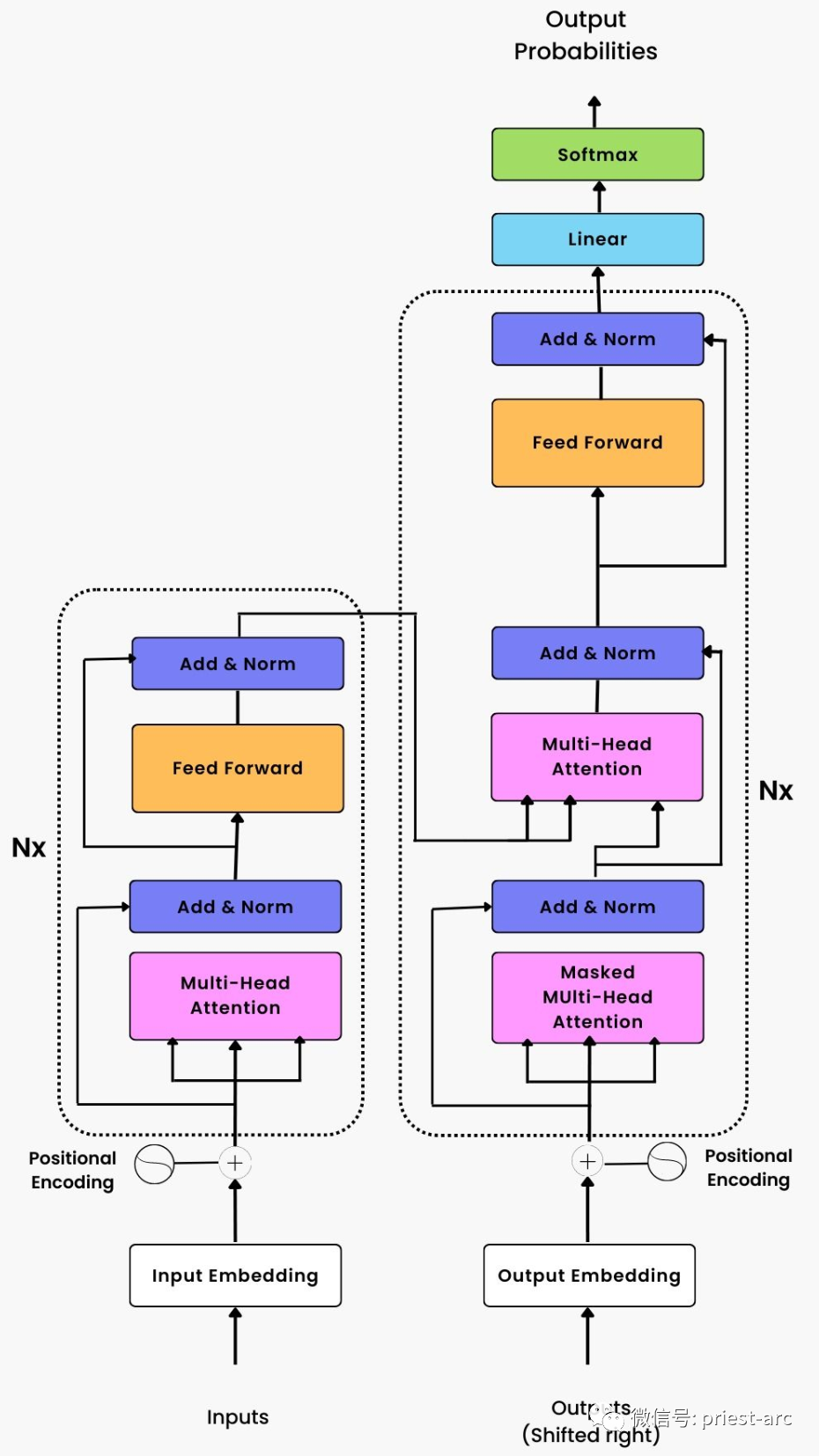
AI代碼解釋 針對 Transformer 的模型通用架構,我們可參考如下所示:
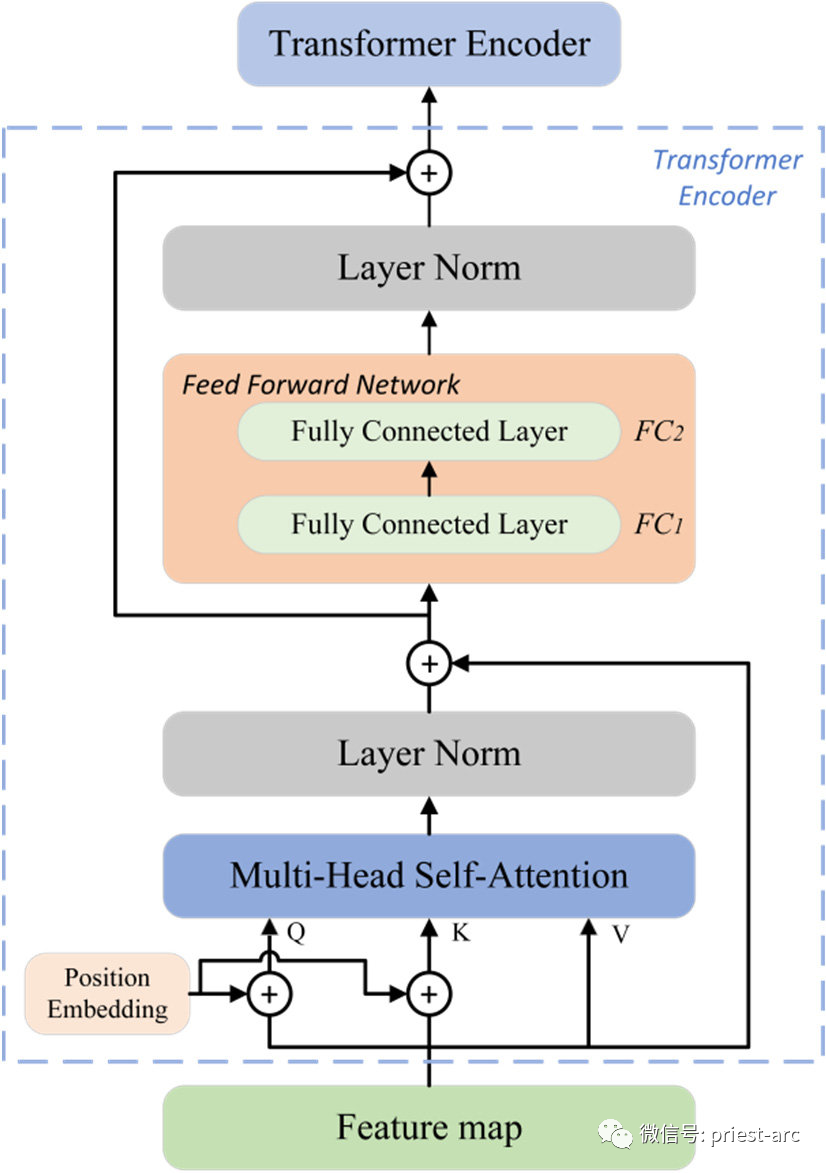
基于如上的 Transformer 深度學習模型的整體架構參考模型圖,我們可以看到:它由兩個主要組件組成: 1、編碼器堆棧 這是由 Nx 個相同的編碼器層組成的堆棧(在原始論文中,Nx=6)。每個編碼器層都由兩個子層組成:多頭自注意力機制和前饋神經網絡。多頭自注意力機制用于對輸入序列中的不同位置之間的關系進行建模,而前饋神經網絡則用于對每個位置進行非線性轉換。編碼器堆棧的作用是將輸入序列轉換為一系列高級特征表示。 Transformer 編碼器的整體架構。我們在 Transformer 編碼器中使用絕對位置嵌入,具體可參考如下:
2、解碼器堆棧 這也是由 Nx 個相同的解碼器層組成的堆棧(在原始論文中,Nx=6)。每個解碼器層除了包含編碼器層的兩個子層外,還包含一個額外的多頭自注意力機制子層。這個額外的自注意力機制用于對編碼器堆棧的輸出進行關注,并幫助解碼器對輸入序列中的信息進行解碼和生成輸出序列。 在編碼器和解碼器堆棧之間,還有一個位置編碼層。這個位置編碼層的作用是利用序列的順序信息,為輸入序列中的每個位置提供一個固定的編碼表示。這樣,模型可以在沒有遞歸或卷積操作的情況下,利用位置編碼層來處理序列的順序信息。 Transformer 解碼器的整體架構,具體可參考如下所示:
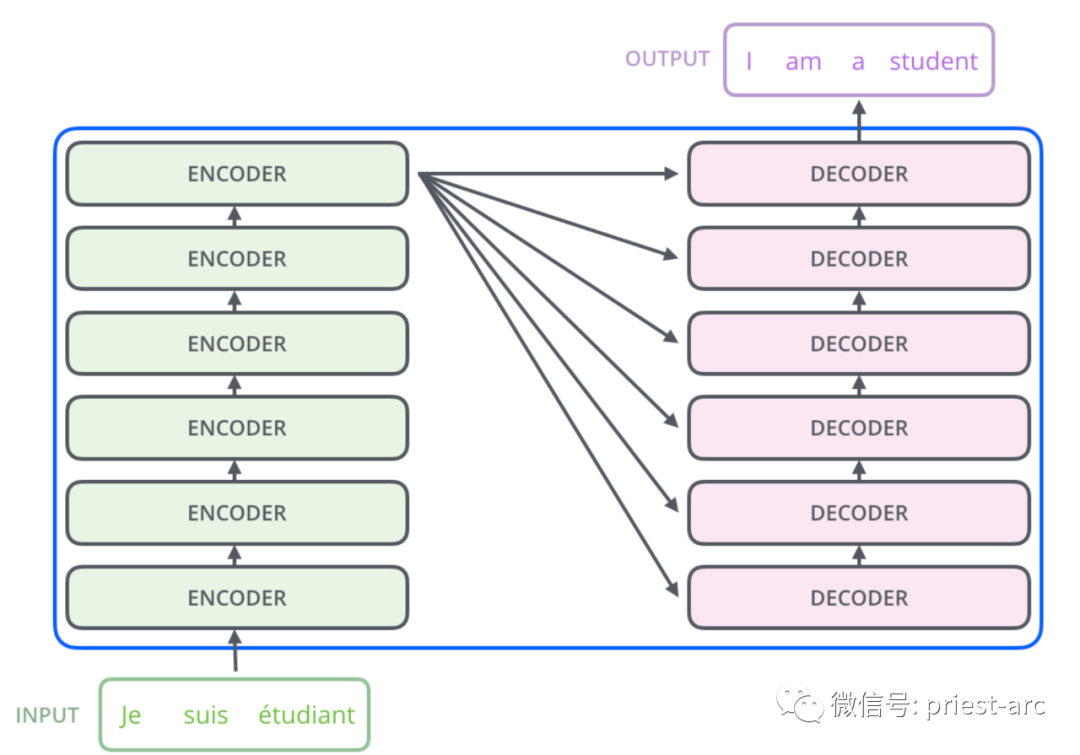
在實際的場景中,兩者的互動關系如下:
— 04 — 什么是 Transformer 神經網絡?眾所周知,Transformer 在處理文本序列、基因組序列、聲音和時間序列數據等神經網絡設計中起著關鍵作用。其中,自然語言處理是 Transformer 神經網絡最常見的應用領域。 當給定一個向量序列時,Transformer 神經網絡會對這些向量進行編碼,并將其解碼回原始形式。而 Transformer 的注意力機制則是其不可或缺的核心組成部分。注意力機制表明了在輸入序列中,對于給定標記的編碼,其周圍其他標記的上下文信息的重要性。 打個比方,在機器翻譯模型中,注意力機制使得 Transformer 能夠根據所有相關單詞的上下文,將英語中的"it"正確翻譯為法語或西班牙語中的性別對應的詞匯。 Transformers 能夠利用注意力機制來確定如何翻譯當前單詞,同時考慮其周圍單詞的影響。 然而,需要注意的是,Transformer 神經網絡取代了早期的循環神經網絡(RNN)、長短期記憶(LSTM)和門控循環單元(GRU)等模型,成為了更為先進和有效的選擇。
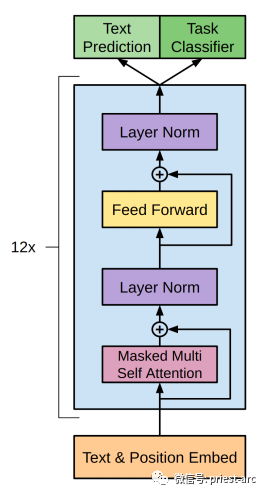
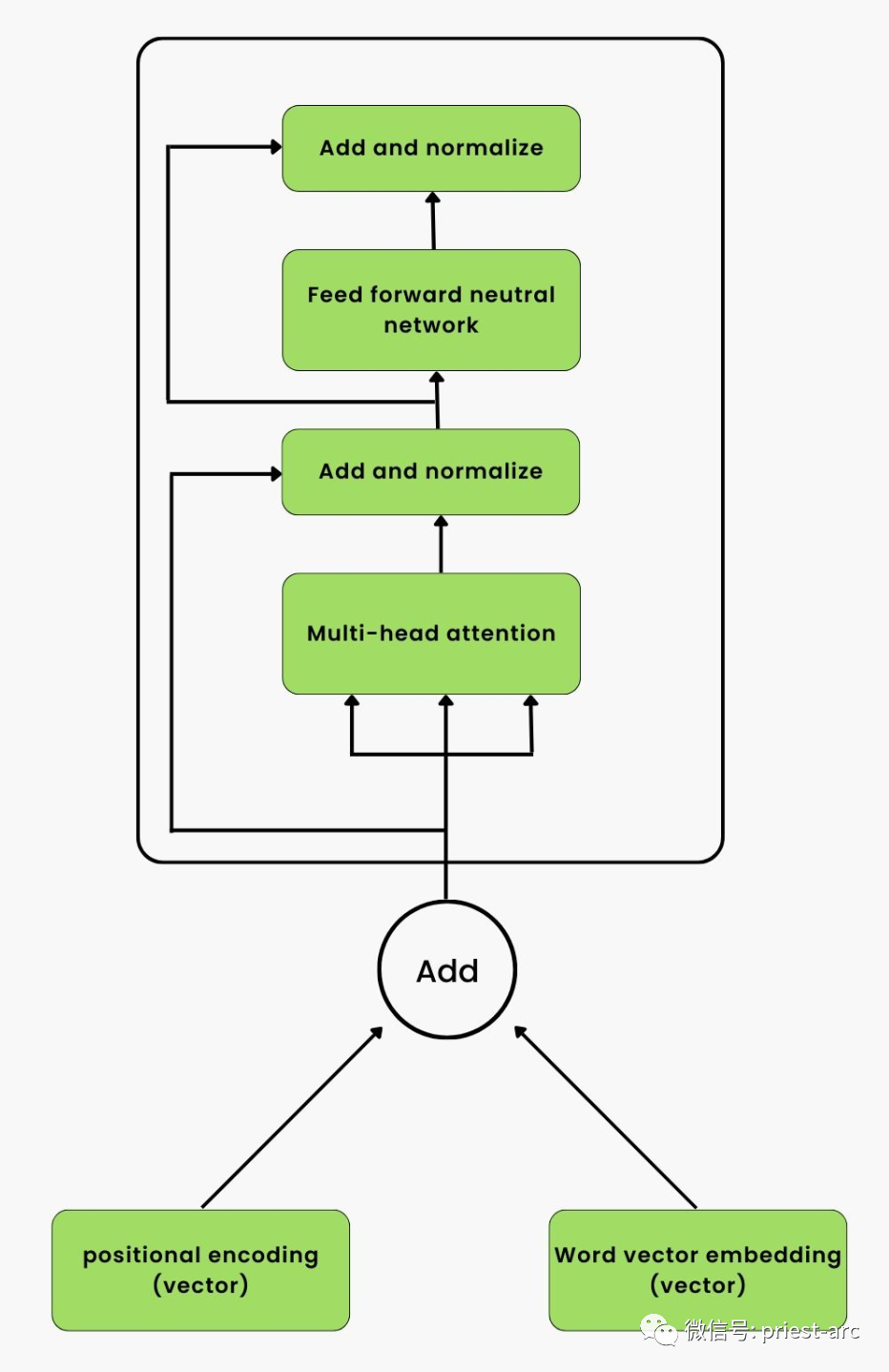
通常而言,Transformer 神經網絡接受輸入句子并將其編碼為兩個不同的序列: 1、詞向量嵌入序列 詞向量嵌入是文本的數字表示形式。在這種情況下,神經網絡只能處理轉換為嵌入表示的單詞。字典中的單詞在嵌入表示中表示為向量。 2、位置編碼器序列 位置編碼器將原始文本中單詞的位置表示為向量。Transformer 將詞向量嵌入和位置編碼結合起來。然后,它將組合結果發送到各個編碼器,然后是解碼器。 與 RNN 和 LSTM 按順序提供輸入不同,Transformer 同時提供輸入。每個編碼器將其輸入轉換為另一個向量序列,稱為編碼。 解碼器以相反的順序工作。它將編碼轉換回概率,并根據概率生成輸出單詞。通過使用 softmax 函數,Transformer 可以根據輸出概率生成句子。 每個解碼器和編碼器中都有一個稱為注意力機制的組件。它允許一個輸入單詞使用其他單詞的相關信息進行處理,同時屏蔽不包含相關信息的單詞。 為了充分利用 GPU 提供的并行計算能力,Transformer 使用多頭注意力機制進行并行實現。多頭注意力機制允許同時處理多個注意力機制,從而提高計算效率。 相比于 LSTM 和 RNN,Transformer 深度學習模型的優勢之一是能夠同時處理多個單詞。這得益于 Transformer 的并行計算能力,使得它能夠更高效地處理序列數據。 — 05 — 常見的 Transformer 模型截止目前,Transformer 是構建世界上大多數最先進模型的主要架構之一。它在各個領域取得了巨大成功,包括但不限于以下任務:語音識別到文本轉換、機器翻譯、文本生成、釋義、問答和情感分析。這些任務中涌現出了一些最優秀和最著名的模型。
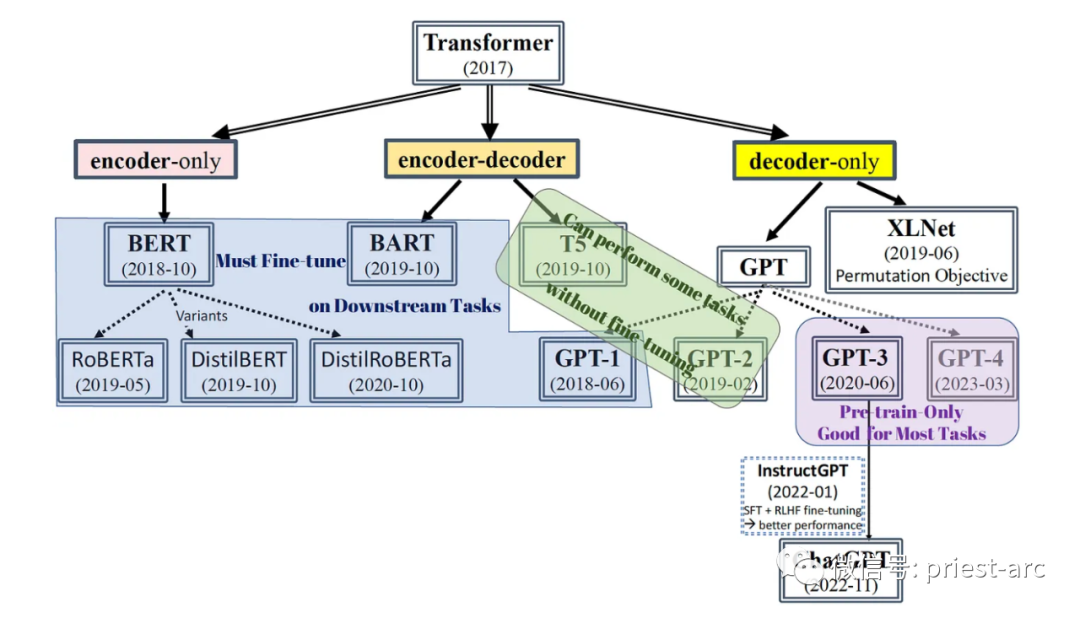
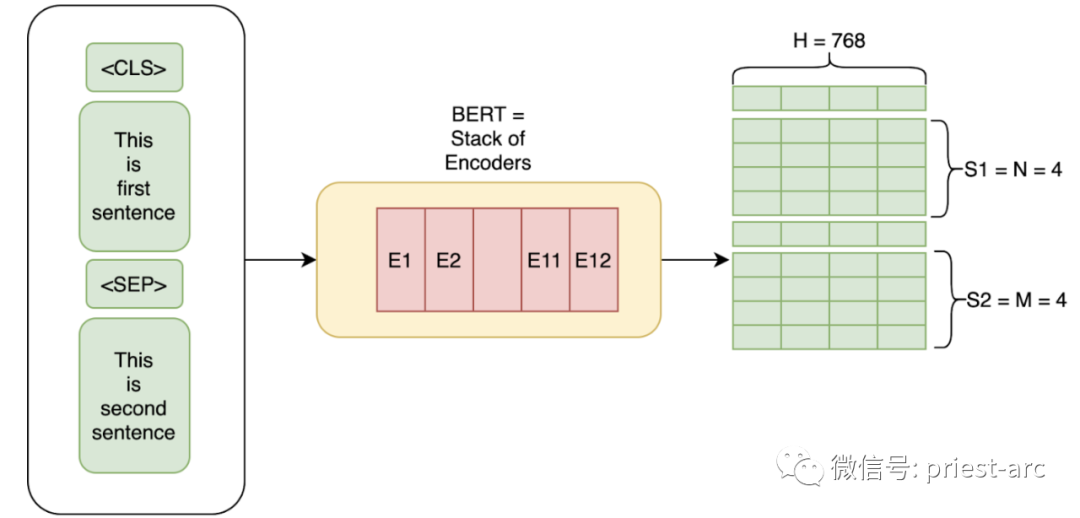
基于 Transformer 的模型體系圖 1、BERT(雙向編碼器表示的 Transformer ) 作為一種由 Google 設計的技術,針對自然語言處理而開發,基于預訓練的 Transformer 模型,當前被廣泛應用于各種 NLP 任務中。 在此項技術中,雙向編碼器表示轉化為了自然語言處理的重要里程碑。通過預訓練的 Transformer 模型,雙向編碼器表示(BERT)在自然語言理解任務中取得了顯著的突破。BERT 的意義如此重大,以至于在 2020 年,幾乎每個英語查詢在 Google 搜索引擎中都采用了 BERT 技術。 BERT 的核心思想是通過在大規模無標簽的文本數據上進行預訓練,使模型學習到豐富的語言表示。BERT 模型具備雙向性,能夠同時考慮一個詞在上下文中的左側和右側信息,從而更好地捕捉詞語的語義和語境。
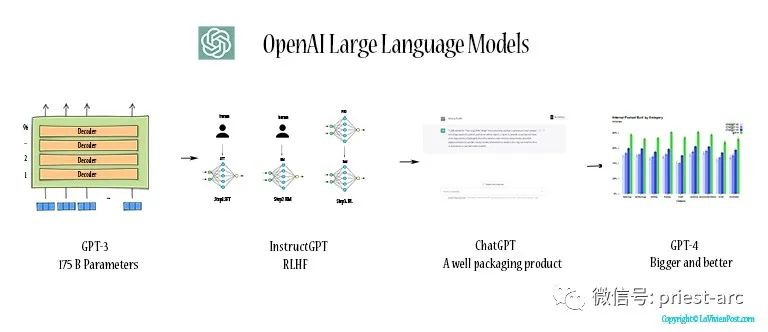
BERT 的成功標志著 Transformer 架構在 NLP 領域的重要地位,并在實際應用中取得了巨大的影響。它為自然語言處理領域帶來了重大的進步,并為搜索引擎等應用提供了更準確、更智能的語義理解。 2、GPT-2 / GPT-3(生成預訓練語言模型) 生成式預訓練 Transformer 2和3分別代表了最先進的自然語言處理模型。其中,GPT(Generative Pre-trained Transformer)是一種開源的 AI 模型,專注于處理自然語言處理(NLP)相關任務,如機器翻譯、問答、文本摘要等。 上述兩個模型的最顯著區別在于“規模”和“功能”。具體而言,GPT-3 是最新的模型,相比于 GPT-2,其引入了許多新的功能和改進。除此之外,GPT-3 的模型容量達到了驚人的 1750 億個機器學習參數,而 GPT-2 只有 15 億個參數。 具備如此巨大的參數容量,GPT-3 在自然語言處理任務中展現出了令人驚嘆的性能。它具備更強大的語言理解和生成能力,能夠更準確地理解和生成自然語言文本。此外,GPT-3 在生成文本方面尤為出色,能夠生成連貫、富有邏輯的文章、對話和故事。 GPT-3 的性能提升得益于其龐大的參數規模和更先進的架構設計。它通過在大規模文本數據上進行預訓練,使得模型能夠學習到更深入、更全面的語言知識,從而使得 GPT-3 能夠成為目前最強大、最先進的生成式預訓練 Transformer 模型之一。
當然,除了上面的 2 個核心模型外,T5、BART 和 XLNet 也是 Transformer(Vaswani 等人,2017)家族的成員。這些模型利用 Transformer 的編碼器、解碼器或兩者來進行語言理解或文本生成。由于篇幅原因,暫不在本篇博文中贅述。 — 05 — Transformer 模型并不是完美的與基于 RNN 的 seq2seq 模型相比,盡管 Transformer 模型在自然語言處理領域取得了巨大的成功,然而,其本身也存在一些局限性,主要包括以下幾個方面: 1、高計算資源需求 Transformer 模型通常需要大量的計算資源進行訓練和推理。由于模型參數眾多且復雜,需要顯著的計算能力和存儲資源來支持其運行,從而使得在資源受限的環境下應用 Transformer 模型變得相對困難。 2、長文本處理困難 在某些特定的場景下,由于 Transformer 模型中自注意力機制的特性,其對于長文本的處理存在一定的困難。隨著文本長度的增加,模型的計算復雜度和存儲需求也會顯著增加。因此,對于超長文本的處理,Transformer 模型可能會面臨性能下降或無法處理的問題。 3、缺乏實際推理機制 在實際的業務場景中,Transformer 模型通常是通過在大規模數據上進行預訓練,然后在特定任務上進行微調來實現高性能,從而使得模型在實際推理過程中對于新領域或特定任務的適應性有限。因此,對于新領域或特定任務,我們往往需要進行額外的訓練或調整,以提高模型的性能。 4、對訓練數據的依賴性 Transformer 模型在預訓練階段需要大量的無標簽數據進行訓練,這使得對于資源受限或特定領域數據稀缺的情況下應用 Transformer 模型變得困難。此外,模型對于訓練數據的質量和多樣性也有一定的依賴性,不同質量和領域的數據可能會對模型的性能產生影響。 5、缺乏常識推理和推理能力 盡管 Transformer 模型在語言生成和理解任務上取得了顯著進展,但其在常識推理和推理能力方面仍存在一定的局限性。模型在處理復雜推理、邏輯推斷和抽象推理等任務時可能表現不佳,需要進一步的研究和改進。 盡管存在這些局限性,Transformer 模型仍然是當前最成功和最先進的自然語言處理模型之一,為許多 NLP 任務提供了強大的解決方案。未來的研究和發展努力將有助于克服這些局限性,并推進自然語言處理領域的進一步發展。 Reference : [1] https://developers.google.com/machine-learning [2] https://www.turing.com/kb/brief-introduction-to-transformers-and-their-power 閱讀原文:https://cloud.tencent.com/developer/article/2332194 該文章在 2025/6/18 9:11:46 編輯過 |
關鍵字查詢
相關文章
正在查詢... 



|


 400 186 1886
400 186 1886



 ?
?