當我們需要在網絡間傳輸數據或將數據存儲到本地存儲時,我們通常會將JavaScript對象轉換為字符串,然后在需要時再將其轉換回對象,這就是數據序列化與反序列化。雖然JSON.parse()和JSON.stringify()是JavaScript中最常用的序列化和反序列化方法,但它們并非適用于所有場景,有時甚至會成為應用性能的瓶頸。
基礎知識:JSON.parse的工作原理與局限性
JSON.parse()是JavaScript內置的反序列化方法,它將JSON字符串轉換為JavaScript對象:
const jsonString = '{"name":"張三","age":30,"isActive":true}';
const obj = JSON.parse(jsonString);
console.log(obj.name); // 輸出:張三
雖然JSON.parse()使用簡單,但它有一些局限性:
- 性能問題:在處理大型JSON數據時,
JSON.parse()可能會導致主線程阻塞,影響用戶體驗。 - 數據類型限制:它無法正確處理日期、函數、undefined、NaN、正則表達式等JavaScript特有的數據類型。
- 安全風險:解析不受信任的JSON數據可能帶來安全隱患。
提升反序列化效率的策略
1. 使用reviver函數處理特殊數據類型
JSON.parse()接受第二個參數reviver,這是一個函數,可以在反序列化過程中轉換值:
const jsonWithDate = '{"name":"張三","birthDate":"2000-01-01T00:00:00.000Z"}';
const objWithDate = JSON.parse(jsonWithDate, (key, value) => {
if (key === 'birthDate') {
return new Date(value);
}
return value;
});
console.log(objWithDate.birthDate instanceof Date); // 輸出:true
2. 流式解析大型JSON
對于大型JSON數據,可以考慮使用流式解析庫,如oboe.js或stream-json:
3. 使用二進制格式代替JSON
在某些性能關鍵的場景中,可以考慮使用二進制格式如MessagePack、Protocol Buffers或BSON:
二進制格式通常比JSON更緊湊,解析速度更快,但可讀性較差,適用于內部系統通信而非API接口。
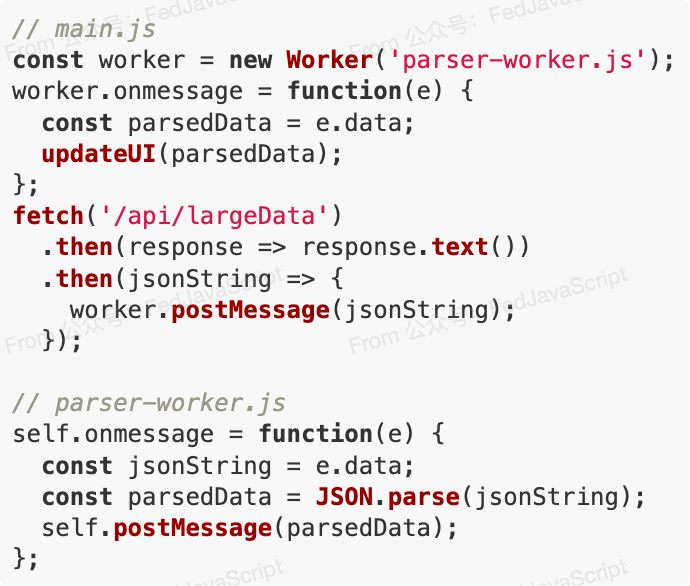
4. 使用Web Workers卸載解析工作
為避免大型JSON解析阻塞主線程,可以將解析工作卸載到Web Worker中:
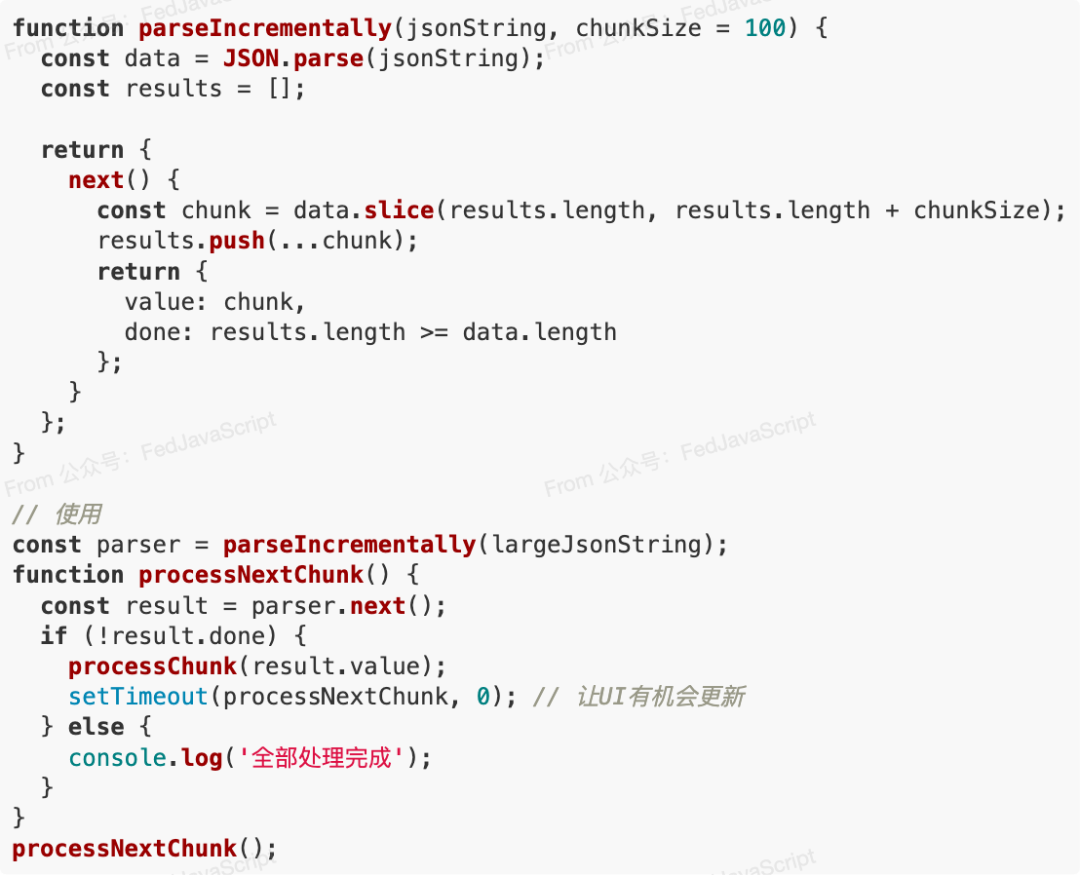
5. 增量解析與懶加載
對于特別大的數據集,可以實現增量解析和懶加載策略:
性能對比與基準測試
不同反序列化方法的性能可能因數據大小和復雜度而異。以下是一些基準測試結果:
// 性能測試代碼
function benchmarkParse() {
const data = { /* 測試數據 */ };
const jsonString = JSON.stringify(data);
console.time('JSON.parse');
for (let i = 0; i < 1000; i++) {
JSON.parse(jsonString);
}
console.timeEnd('JSON.parse');
const msgpackData = msgpack.encode(data);
console.time('msgpack');
for (let i = 0; i < 1000; i++) {
msgpack.decode(msgpackData);
}
console.timeEnd('msgpack');
}
典型結果顯示:
- 小數據集(<10KB):JSON.parse性能足夠好
- 中等數據集(10KB-1MB):MessagePack等二進制格式開始顯示優勢
- 大數據集(>1MB):流式解析或Web Worker方案效果最佳
在JavaScript中,高效的反序列化不僅僅是選擇正確的庫或API,更是根據應用場景選擇適當的策略。對于小型數據,標準的JSON.parse()通常足夠;對于大型數據,可能需要考慮流式解析、Web Workers或二進制格式;而對于具有特殊要求的應用,自定義序列化方案可能是最佳選擇。
閱讀原文:https://mp.weixin.qq.com/s/anc_tlGkOh4OeVHpgMyFbw
該文章在 2025/5/21 9:35:59 編輯過








 400 186 1886
400 186 1886


